Overview
We develop Auto-J, a new open-source generative judge that can effectively evaluate different LLMs on how they align to human preference. It is featured with:
- Generality: Auto-J is trained on data from real-world user queries and responses from various LLMs, covering a wide range of 58 real-world scenarios.
- Flexibility: Auto-J supports both pairwise response comparison and single-response evaluation by just switching to corresponding prompts.
- Interpretability: Auto-J provides detailed critiques that enhance the reliability of its evaluation outcomes and facilitate humans' involvement in the evaluation loop.
Leaderboard
We present the benchmarking results for two tasks: the pairwise response comparison leaderboard and the critique generation leaderboard.
For the pairwise comparison task, the metric evaluates agreement with human preferences and the consistency rate when responses are swapped (not applicable for independent/single rating methods). Results may vary slightly from our paper due to modifications in verdict extraction codes for some models.
| Ranking | Model | Type | Generative | Agreement | Consistency |
|---|---|---|---|---|---|
| 1 | GPT-4 | Pairwise | ✔️ | 62.28 | 86.28 |
| 2 | Auto-J (Ours) | Pairwise | ✔️ | 54.96 | 83.41 |
| 3 | Moss-RM | Single | ❌ | 54.31 | - |
| 4 | Ziya-RM | Single | ❌ | 53.23 | - |
| 5 | Beaver-RM | Single | ❌ | 52.37 | - |
| 6 | OASST-RM | Single | ❌ | 51.08 | - |
| 7 | LLaMA-2-70B-Chat | Pairwise | ✔️ | 46.12 | 69.90 |
| 8 | ChatGPT | Pairwise | ✔️ | 42.74 | 62.43 |
| 9 | Claude-2 | Pairwise | ✔️ | 42.60 | 63.43 |
| 10 | SteamSHP | Pairwise | ✔️ | 40.59 | 65.59 |
| 11 | PandaLM | Pairwise | ✔️ | 39.44 | 66.88 |
| 12 | Vicuna-13B-v1.5 | Pairwise | ✔️ | 39.22 | 62.07 |
| 13 | WizardLM-13B-v1.5 | Pairwise | ✔️ | 36.35 | 57.69 |
| 14 | LLaMA-2-13B-Chat | Pairwise | ✔️ | 29.81 | 48.56 |
In the critique generation task, the metric measures the win-rate against critiques generated by a reference model (ChatGPT) as judged by GPT-4.
| Ranking | Model | Win | Tie | Lose |
|---|---|---|---|---|
| 1 | Auto-J (Ours) | 73.7 | 2.2 | 24.1 |
| 2 | GPT-4 | 58.2 | 7.3 | 34.5 |
| 3 | ChatGPT (Reference) | 50.0 | 0.0 | 50.0 |
| 4 | LLaMA-2-13B-Chat | 47.0 | 3.9 | 49.1 |
| 5 | WizardLM-13B-v1.5 | 38.8 | 7.7 | 53.5 |
| 6 | Vicuna-13B-v1.5 | 35.4 | 7.3 | 57.3 |
| 7 | SelFee | 12.9 | 1.7 | 85.4 |
Demo


Methodology
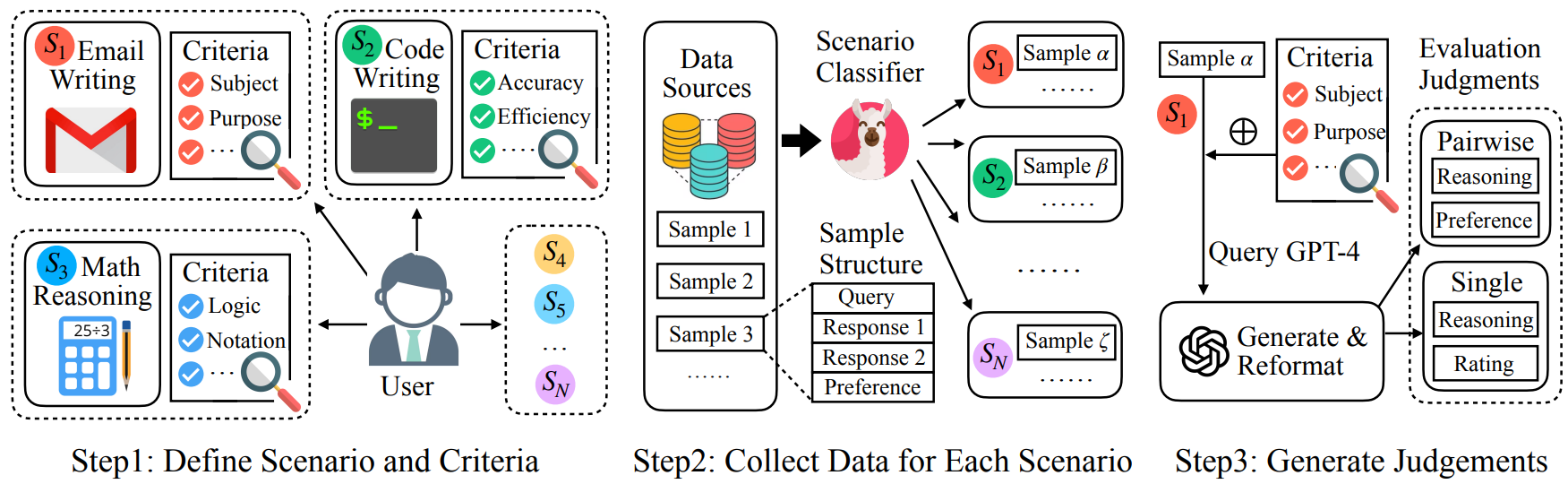
We begin by defining 58 scenarios, which we then condense into 8 major groups. Each scenario is accompanied by a set of manually designed criteria. We collect real-world user queries and responses from various chatbots and categorize the queries using our newly trained scenario classifier. We then employ GPT-4 to generate judgments for both our pairwise data (3,436 samples) and single-response data (960 samples) using the respective scenario criteria as a reference. Specifically, GPT-4 is tasked with providing comprehensive judgments for each data sample, considering both the predefined criteria for each scenario and brainstorming specific points. The judgment for pairwise response comparison contains the key factors in distinguishing between the two responses and the final verdict (i.e., which response is better or if they are tied), while the judgment for single-response evaluation includes critiques and an overall rating. These judgments, together with the user queries and responses, form our training data. During training, we utilize both pairwise comparisons and single-response data to train Auto-J, enabling it to seamlessly switch between these two evaluation protocols by simply applying the appropriate prompts. We also create new testbeds with a balanced distribution on different scenarios to assess Auto-J's effectiveness in pairwise response comparison and single-response evaluation.
Results