🏆Leaderboard
Due to the opacity of the training process, comparing large language models (LLMs) directly introduces a potential unfairness, thus impacting the healthy development of the field of LLMs.
This leaderboard shows the relative possibility that various models conduct verbatim training on the training set of a benchmark over test set to enhance capabilities (measured based on PPL and N-gram Accuracy). Models exhibiting near-zero possibilities suggest either the absence of training and test split or the use of both splits in the training process. This metric does not imply cheating, but rather indicates the potential use of the benchmark data during the (pre-)training phase; while using benchmarks to enhance capabilities is acceptable, the lack of relevant documentation can reduce transparency, potentially resulting in unfair comparisons and hindering the field's healthy development.
GSM8K
| Models | 5-gram | ppl (answer) |
|---|---|---|
| Aquila2-7B | 23.24 | 75.25 |
| InternLM2-20B | 29.11 | 67.77 |
| InternLM2-7B | 30.12 | 64.75 |
| Qwen1.5-7B | 27.38 | 48.78 |
| Qwen1.5-14B | 25.62 | 40.24 |
| Aquila2-34B | 23.12 | 39.78 |
| Qwen-14B | 35.16 | 26.94 |
| Qwen-7B | 35.54 | 25.81 |
| Qwen1.5-1.8B | 25.17 | 17.59 |
| ChatGLM2-6B | 13.65 | 28.76 |
| Qwen-1.8B | 22.87 | 10.30 |
| Baichuan2-13B-Base | 17.85 | 11.82 |
| InternLM-20B | 10.68 | 16.49 |
| Orca-2-7B | 6.45 | 17.10 |
| Yi-34B | 11.55 | 10.19 |
| Yi-6B | 9.05 | 5.30 |
| Aquila-7B | 2.57 | 9.80 |
| Phi-2 | 10.60 | -2.03 |
| InternLM-7B | 3.86 | 4.13 |
| ChatGLM3-6B | 1.57 | 5.43 |
| Yi1.5-34B | 3.41 | 1.84 |
| LLaMA2-7B | 3.82 | -0.29 |
| Yi1.5-6B | 3.42 | 0.05 |
| Phi-1.5 | 4.46 | -1.74 |
| Baichuan-7B | 1.66 | -1.08 |
| Mistral-7B-v0.1 | 0.96 | -0.63 |
| LLaMA-7B | 1.07 | -0.85 |
| Grok-1 | -0.54 | -0.39 |
| Gemma-2B | -0.57 | -1.48 |
| Gemma-7B | -1.91 | -0.70 |
| Llama-3-8B | -2.13 | -0.87 |
| Baichuan2-7B-Base | -2.06 | -1.23 |
| Baichuan-13B-Base | -2.58 | -0.91 |
| InternLM2-20B-Base | -2.42 | -1.16 |
| DeepSeekMath-7B | -2.64 | -0.97 |
| InternLM2-7B-Base | -3.21 | -0.83 |
| Llama-3-8B-Instruct | -4.50 | -0.22 |
MATH
| Models | 5-gram | ppl (answer) |
|---|---|---|
| Aquila2-7B | 15.24 | 158.76 |
| InternLM2-20B | 20.48 | 72.44 |
| Aquila2-34B | 18.50 | 70.23 |
| Yi1.5-6B | 19.21 | 59.88 |
| Yi1.5-34B | 20.55 | 54.17 |
| InternLM2-7B | 17.67 | 45.22 |
| Qwen1.5-1.8B | 8.08 | 23.11 |
| Qwen1.5-7B | 4.74 | 25.32 |
| Qwen1.5-14B | 5.06 | 22.20 |
| Qwen-14B | 3.15 | 20.34 |
| Qwen-7B | 4.20 | 17.60 |
| Qwen-1.8B | 9.94 | 9.79 |
| ChatGLM3-6B | 5.33 | 9.69 |
| InternLM-7B | 4.11 | 6.05 |
| InternLM-20B | 0.71 | 4.85 |
| Gemma-2B | 2.66 | 1.05 |
| Orca-2-7b | 2.24 | 1.31 |
| Llama-3-8B | 3.06 | -0.01 |
| Gemma-7B | 3.54 | -0.63 |
| Yi-6B | 3.05 | -0.55 |
| Yi-34B | 2.81 | -0.60 |
| Llama-3-8B-instruct | 2.47 | -0.28 |
| Grok-1 | 0.36 | 1.39 |
| Phi-2 | 2.07 | -0.41 |
| LLaMA-7B | 2.28 | -0.88 |
| DeepSeekMath-7b | 1.34 | -0.64 |
| ChatGLM2-6B | 1.57 | -0.92 |
| InternLM2-7B-Base | 0.58 | -0.20 |
| Phi-1.5 | 0.78 | -0.43 |
| LLaMA2-7B | 0.09 | 0.18 |
| Baichuan-7B | 0.15 | -0.09 |
| InternLM2-20B-Base | 0.46 | -0.61 |
| Baichuan2-7B-Base | -0.58 | -0.13 |
| Mistral-7B-v0.1 | -0.49 | -0.62 |
| Baichuan-13B-Base | -0.61 | -0.53 |
| Aquila-7B | -2.10 | 0.48 |
| Baichuan2-13B-Base | -2.40 | -0.56 |
🚀 Brief Introduction
Amid the expanding use of pre-training data, the phenomenon of benchmark dataset leakage has become increasingly prominent, exacerbated by opaque training processes and the often undisclosed inclusion of supervised data in contemporary Large Language Models (LLMs). This issue skews benchmark effectiveness and fosters potentially unfair comparisons, impeding the field's healthy development. Given that training data and model details are often opaque, and the leakage detection is influenced by various factors such as mode size and training strategies, detecting benchmark leakage is not a trivial task. In this work, we are not pursuing technical contributions in system development; instead, we are attempting to encourage the healthy development of this field, particularly through the lens of mathematical reasoning tasks, in the following aspects:
- Summaries of various pre-training behaviors and challenges for detecting benchmark leakage.
- Proposal of a detection pipeline for estimating pre-training behaviors: We introduce a simple, computationally efficient, and scalable pipeline that leverages two fundamental yet insightful atomic metrics: Perplexity and N-gram Accuracy. These metrics effectively encapsulate the essence of language modeling, capturing its nuances from continuous and discrete perspectives, respectively. By paraphrasing benchmarks to create varied reference versions, we can detect discrepancies in models' atomic metrics, thereby identifying potential data leakage. This pipeline's validity is supported by thorough meta-experiments.
- Leakage analysis of existing models: We extend our investigation to analyze existing models (i.e., 31 open-source LLMs), revealing that, in addition to previously identified leaks, many (i.e., approximately half of them), including well-known language models, may have inadvertently leveraged training data to boost their performance on mathematical reasoning tasks, leading to unfair advantages. Moreover, our metric even enables instance-level detection, revealing the possibility of test set leaks in many models. For example, we found that Qwen-1.8B can accurately predict all 5-grams in 223 examples from the GSM8K training set and 67 from the MATH training set, with an additional 25 correct predictions even in the MATH test set.
- Recommendation for model documentation, benchmark setup and future evaluations: Based on these findings, we offer suggestions encompassing model documentation, benchmark construction, public access to benchmarks, and evaluation from multiple perspectives. We particularly emphasize the aspect of model documentation; we recommend that models should be accompanied by a document at release, which registers whether benchmark data was used for specific performance enhancement and whether any data augmentation was conducted. To this end, we introduce the Benchmark Transparency Card to facilitate this process, hoping that it will be widely adopted to promote transparency and healthy development of LLMs.
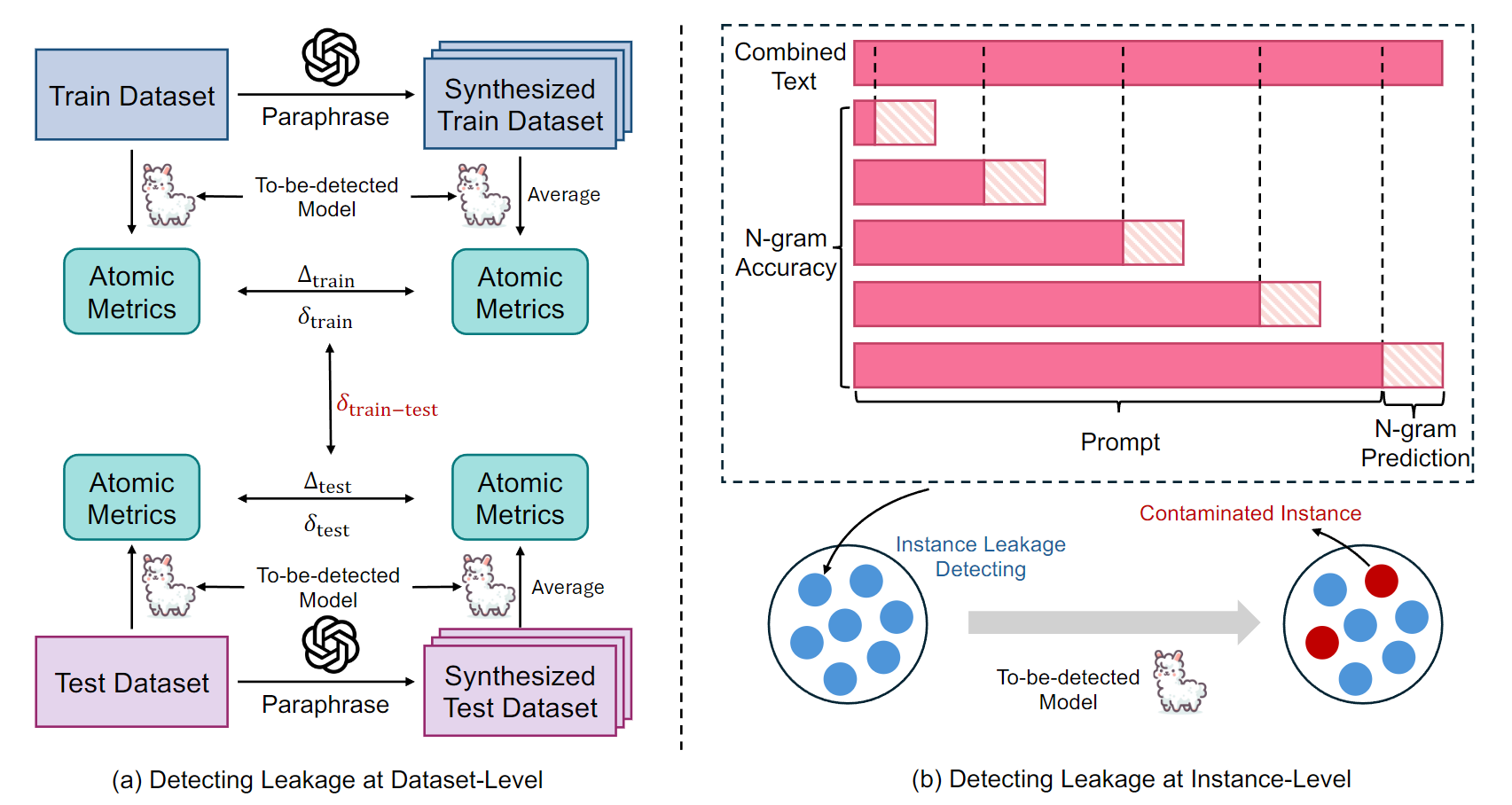
Overview of detection pipeline
📊 N-gram Accuracy Helps Instance-level Leakage Detection
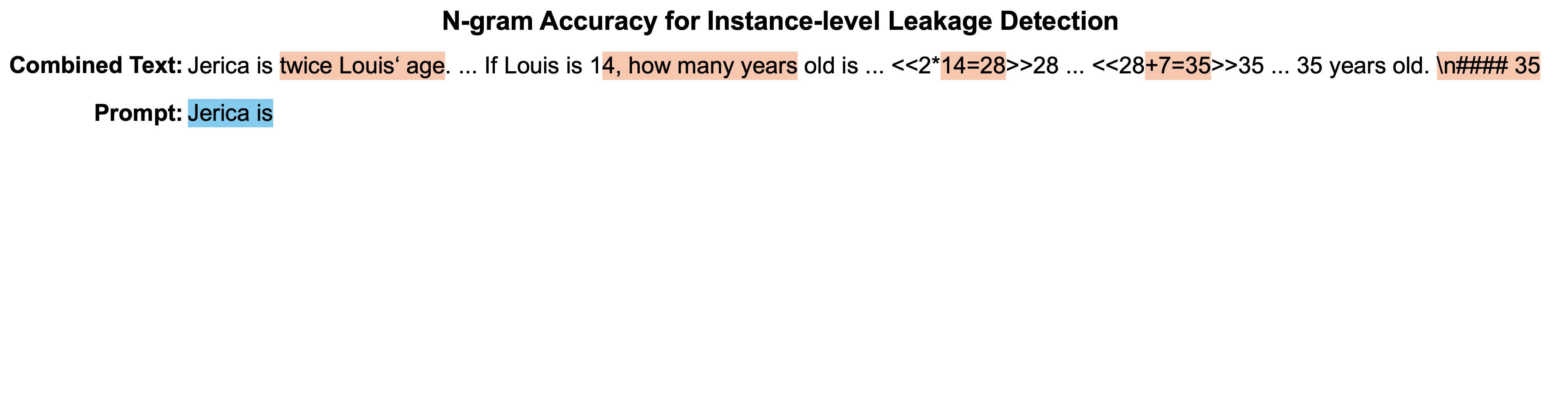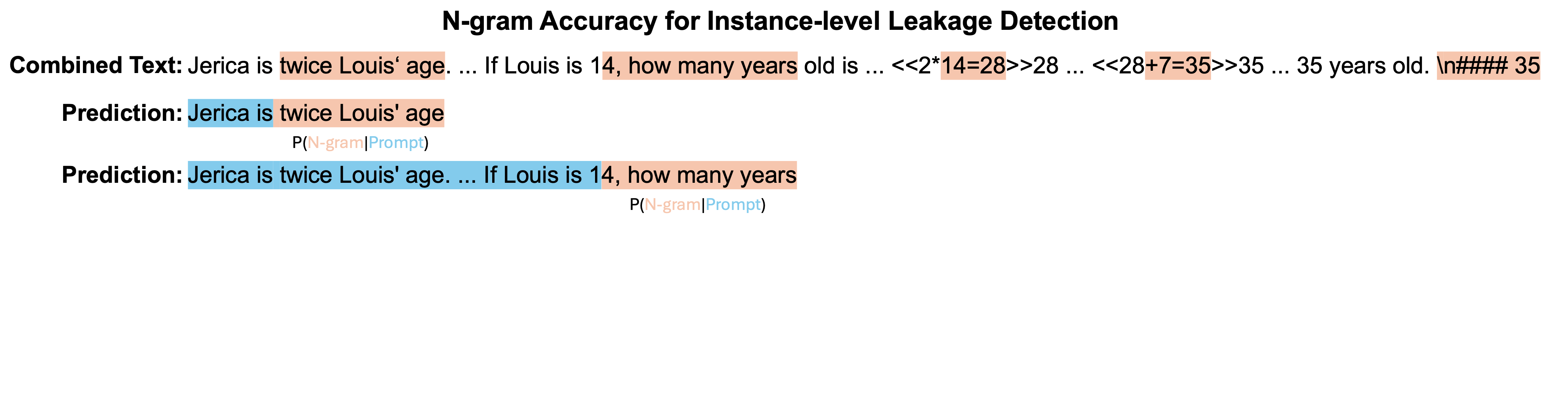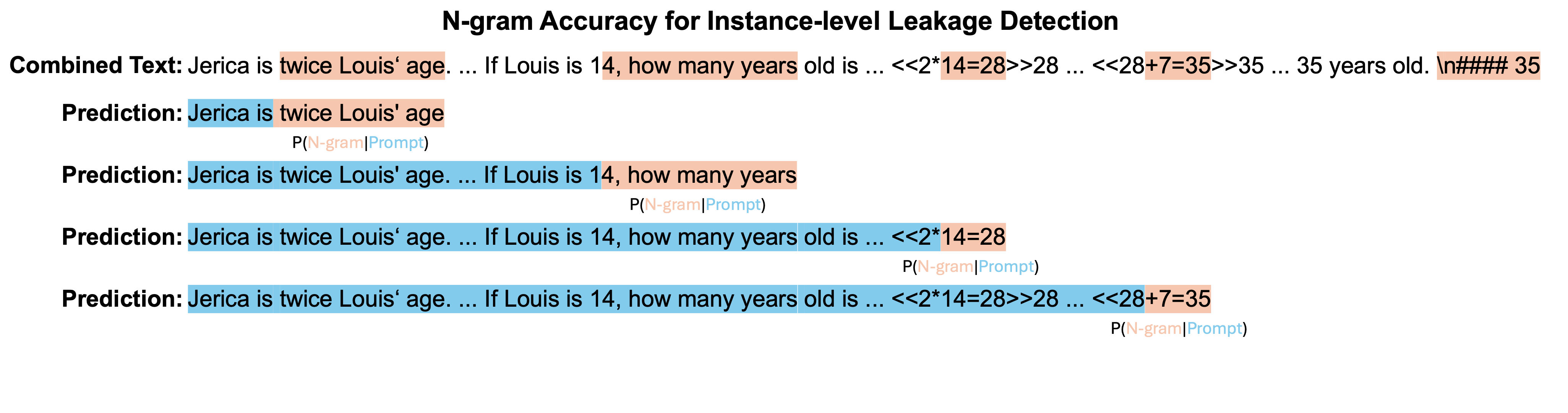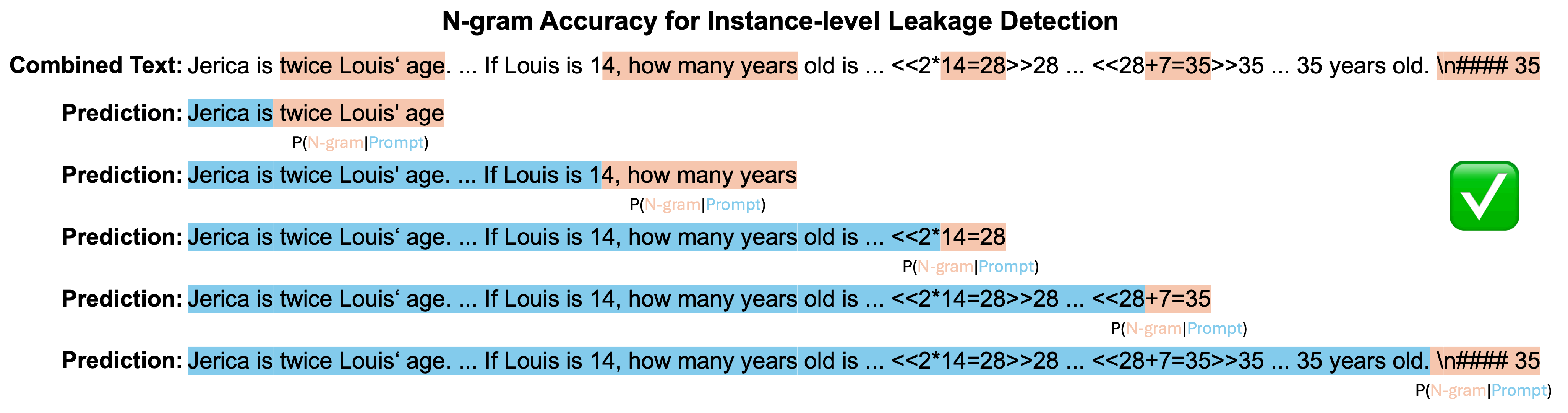
High prediction accuracy for each n-gram of an example's prediction suggests a high probability that the sample was encountered during the training process. To investigate instance-level leakage, we looked closer at n-gram predictions across different models. Additionally, considering that benchmark data may undergo reformatting, paraphrasing, or other modifications when integrated into model training, we leverage lenient metrics, such as ROUGE-L and edit distance similarity, for comparing n-grams. Under this context, an instance is deemed correctly predicted if it achieves an Exact Match (meaning all predictions align perfectly), or if the edit distance similarity of all predictions exceeds 0.9 (indicating substantial similarity), and further, if the ROUGE-L score of all predictions surpasses 0.75.
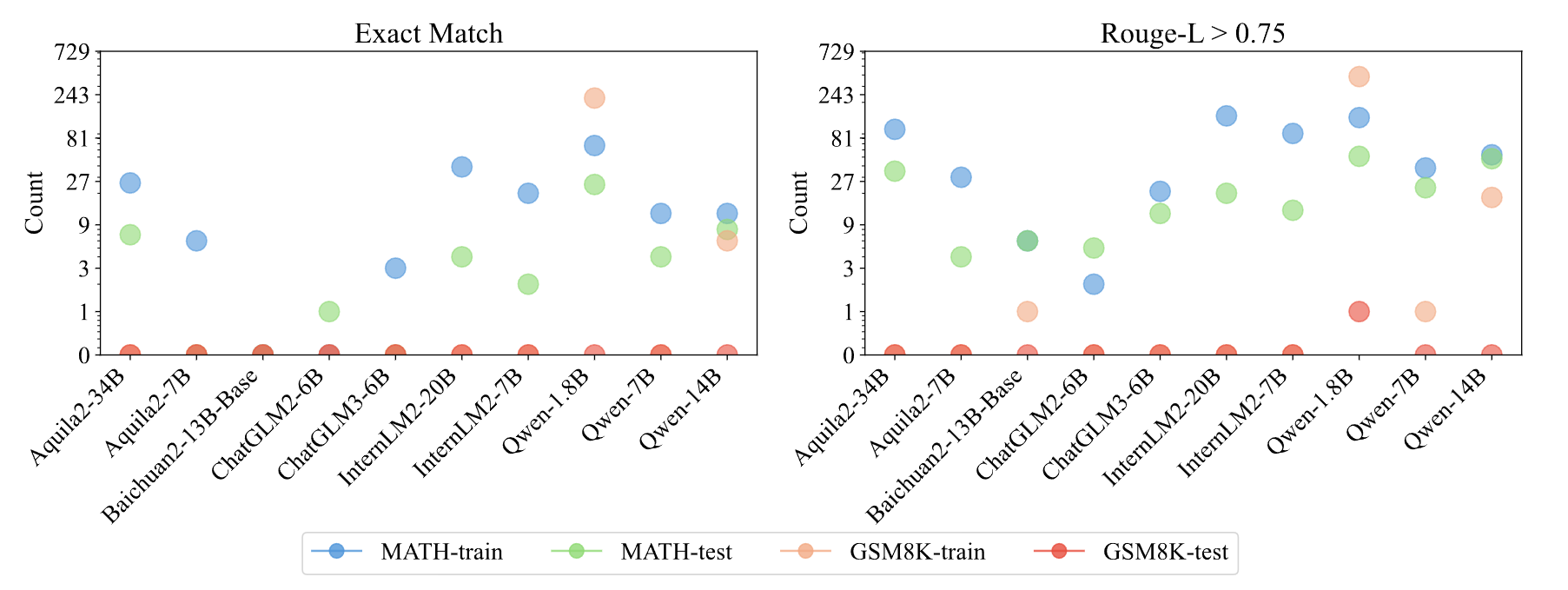
Statistics of suspicious leaked sample, where all 5-grams within a sample are predicted correctly, either strictly (measured by Exact Match) or loosely (measured by ROUGE-L). The y-axis employs an exponential scale based on powers of 3.
We can observe that many models can pricisely predict all ngrams of an example from benchmark training set even test set. Surprisingly, Qwen-1.8B can accurately predict all 5-grams in 223 examples from the GSM8K training set and 67 from the MATH training set, with an additional 25 correct predictions even in the MATH test set. We would like to emphasize that the n-gram accuracy metric can mitigate issues in our detection pipeline, particularly when the training and test datasets are simultaneously leaked and remain undetected. However, this also has its limitations; it can only detect examples that are integrated into the model training in their original format and wording, unless we know the organizational format of the training data used by the model in advance.
📚 Case Study
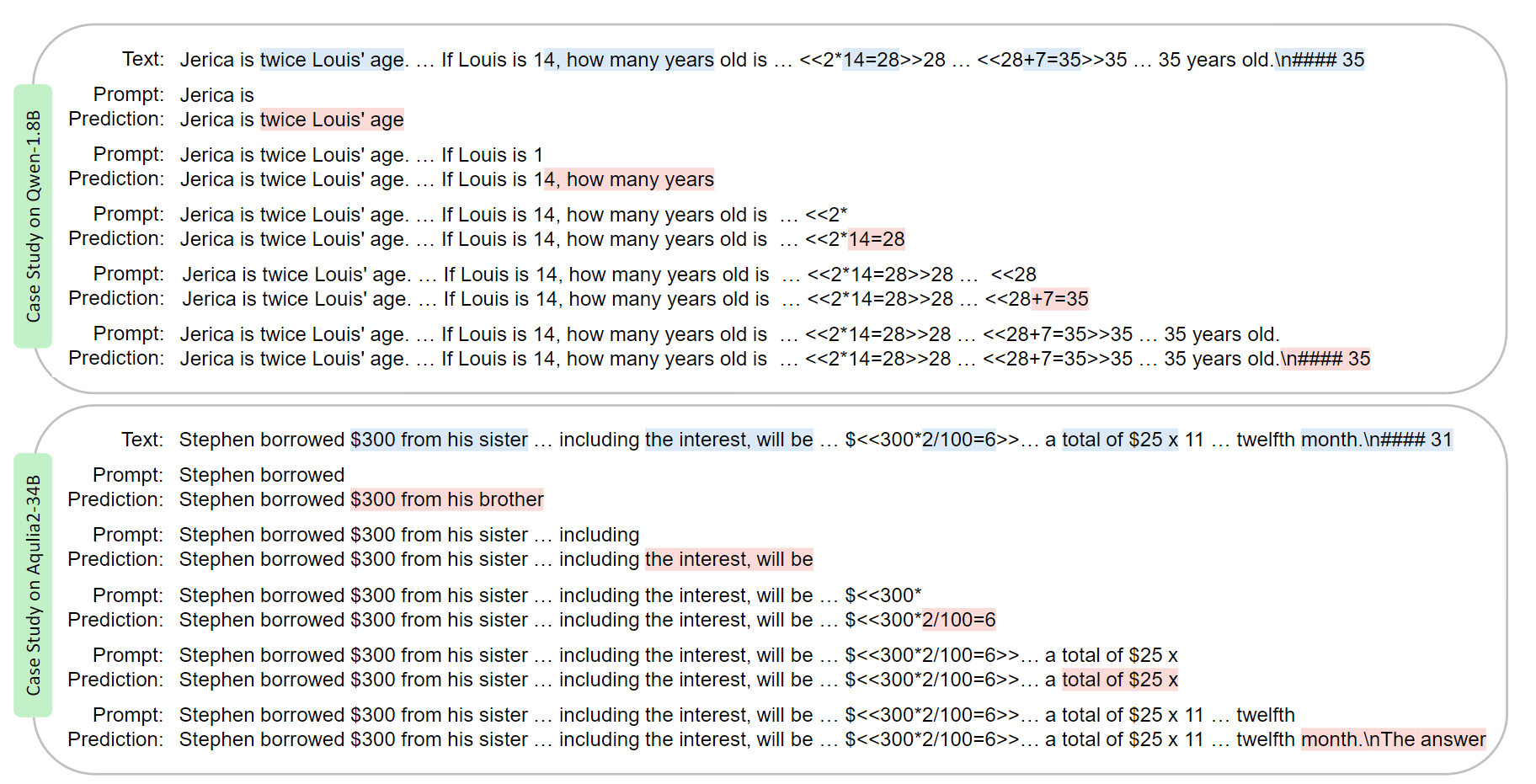
Two cases: one from the GSM8K training set predicted by the Qwen-1.8B model (above), and one from the GSM8K test set by the Aquila2-34B model (below). Both examples are presented with the original question and answer concatenated, separated by a space.
In the first case, the Qwen-1.8B model achieves perfect n-gram predictions on a sample from the GSM8K training set, completing all 5-grams accurately. This strongly suggests potential data leakage within the training set of GSM8K. Additionally, we also conducted a case study on the Aquila2-34B model, known to accidentally be exposed to the entire GSM8K test set. It consistently predicts n-grams as "The answer is" for all instances where the ground truth was represented by a placeholder "####". This observation exactly explains why it is challenging to detect leakage using our n-gram accuracy metric. To enhance readers' comprehension of model behaviors, we have released an interactive demo for case studies, available at Huggingface Space: BenBench.
📃 Recommendation for Model Documentation and Benchmarks Setup
To ensure fairness in the evaluation of large language models moving forward, we propose the following suggestions:
-
Documentation: For any LLMs to be released, comprehensive documentation should be provided. This documentation at least specifies whether the model has been trained on the training or test sets of commonly used benchmarks to prevent potentially unfair comparisons. To this end, we introduce Benchmark Transparency Card, which serves as the supplement of the Data Card and Model Card, aiming to document the utilization of benchmarks (such as whether any benchmark sets are used for training and whether any data augmentation techniques are applied) and benchmark evaluation details. We hope that this card will be widely adopted upon the release of models to foster the healthy development of large language models.
- Benchmark Construction: We recommend constructing benchmarks from the latest corpus to minimize the risk of overlap with pre-training corpora. Additionally, evaluation datasets should be regularly updated using dynamic benchmarks to guard against overfitting to static test datasets.
- Benchmark Public Access: To mitigate the risk of Input-Output Leakage, we advise against directly uploading original benchmarks online, particularly when they contain paired questions and answers. As suggested by Jacovi et al., 2023, encrypting the test set prior to uploading can enhance security. Alternatively, maintaining a private test set through a leaderboard format is also a viable option.
- Evaluation: We recommend caution in drawing overly optimistic conclusions about a model's capabilities based on its strong performance in specific benchmarks. It may be beneficial to evaluate the model further using a variety of contemporary challenges, such as new exam questions, to provide a more balanced assessment of its abilities. When benchmarking proprietary models, it is important to proceed with caution, especially when submitting benchmark data through APIs. There is a risk that this data could be utilized by the model's provider for further training purposes.
BibTeX
@article{xu2024benchmarking,
title={Benchmarking Benchmark Leakage in Large Language Models},
author={Xu, Ruijie and Wang, Zengzhi and Fan, Run-Ze and Liu, Pengfei},
year={2024},
journal={arXiv preprint arXiv:2404.18824},
url={https://arxiv.org/abs/2404.18824}
}