Outline
This section outlines the core of our O1 replication project, guiding readers through our research journey using key questions that reflect the complexity of the process. From our initial evaluation of O1 with the OlympicArena datasets to the construction of long thoughts, our work has involved numerous attempts, iterations, and in-depth analysis of O1’s capabilities.
Each question in this chapter highlights a critical aspect of O1’s cognitive processes. We start by examining the structure of O1’s thoughts and progress to more advanced concepts, such as the development of reward models, on-policy reasoning trees, and how these elements come together in constructing long thoughts. Our methodology, as depicted in our research timeline, emphasizes iterative evaluation and training strategies, combining both quantitative assessments and human feedback.
This question-driven format not only narrates our technical journey but also reflects the broader “journey learning” paradigm we follow, where the process of exploration is just as important as the final outcomes. By sharing our decision-making process, challenges, and innovative solutions, we hope to offer valuable insights to the AI community and encourage further advancements in AI research.
Our journey—marked by persistence, collaboration, and innovation—demonstrates the potential of open research in tackling the challenges of replicating advanced AI models like O1.
Our Research Journey
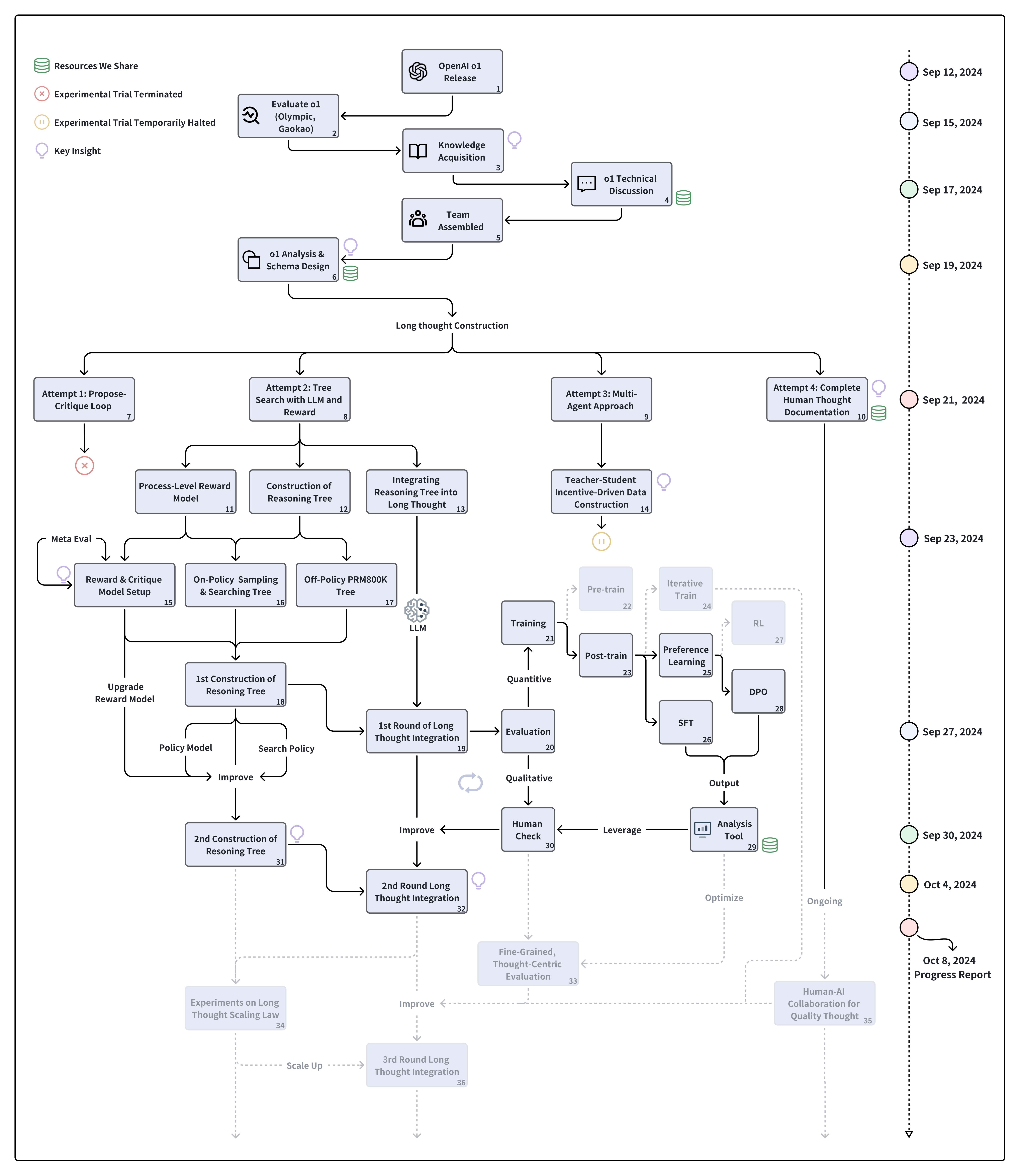 |
|---|
| This figure outlines our research journey exploring OpenAI's o1 technology from its release through October 8, 2024. A timeline tracks our progress chronologically, with research activities flowing vertically in the main diagram. Following the o1 release, we progressed from initial evaluation and knowledge acquisition to team assembly and analysis. Our exploration then focused on four long thought construction attempts: (1) Propose-Critique Loop, (2) Tree Search with LLM and Reward, (3) Multi-Agent Approach, and (4) Complete Human Thought Documentation. The second attempt, our core exploration, splits into three tracks: Process-Level Reward Model, Construction of Reasoning Tree, and Integrating Reasoning Tree into Long Thought. These converge in an iterative cycle of model improvement, including both quantitative and qualitative evaluation. The diagram's right side illustrates our training pipeline, featuring pre-training, iterative training, and optimization techniques. Solid black elements represent completed paths and milestones, while gray dashed elements indicate planned future explorations. This visualization captures both our achievements and future research directions in o1 technology development. |